





Guide du professionnel pour simplifier CI/CD sur IBM i avec Git (Ou pourquoi attendez-vous?)
By Ray Bernardi
J’ai une question pour les entreprises IBM i qui existent. Qu’est-ce que nous attendons ? Pourquoi ne faisons-nous pas encore du DevOps ? Je vais insinuer que beaucoup d’entreprises appartiennent à la catégorie « si ce n’est pas cassé, ne le réparez pas ». C’est à peu près cette culture que les entreprises IBM i traditionnelles ont. C’est aussi la raison pour laquelle les entreprises IBM i sont à la traîne en matière d’innovation et d’adoption de nouvelles technologies et techniques. Cela conduit à l’hypothèse erronée que la plate-forme est vieille et qu’elle ne peut pas répondre aux besoins de l’entreprise. Et pourtant, rien ne pourrait être plus éloigné de la vérité.
Pourtant, je parle à des entreprises qui quittent la plate-forme parce qu’elles ont besoin de se moderniser. Elles sont prêtes à prendre le risque d’un remplacement complet de leurs systèmes d’entreprise. Pourquoi ? Parce qu’elles veulent que le logiciel fonctionnant sur l’IBM i soit aussi agile que l’est leur logiciel au monde « open ». Ils veulent être en capacité d’utiliser le même pipeline pour les changements, quel que soit l’endroit où se trouve le code. Ils veulent automatiser le processus et mettre en œuvre DevOps.
Sommaire
1. C’est la dette technique
Le problème n’est pas la plateforme. Le problème, c’est la dette technique. Leur code est ancien et leur base de données n’a pas été mise à jour en DDL. Ils utilisent encore de vieux systèmes de gestion de changements encombrants, et développés il y a des décennies, qui sont incapables de répondre aux nouvelles exigences agiles auxquelles ils sont confrontés. Ils n’ont aucune idée de la manière d’automatiser ce qui se passe sur l’IBM i ou de le connecter avec les outils qu’ils utilisent à ce jour comme Jenkins, Jira, Git, etc.
2. Quel clivage culturel ?
L’autre problème, c’est la culture. L’IBM i existe depuis longtemps. Beaucoup de gens voient ce qui se passe dans le monde « open » et n’ont aucune idée que cela peut s’appliquer à l’IBM i. La réponse se trouve dans les outils et l’automatisation.
Pourquoi ne pas utiliser les mêmes outils que le monde « open »? Où se trouve votre contrôle de la source pour votre IBM i en ce moment? Est-il contenu dans un système de gestion de changements obsolète? Pourquoi ne pas utiliser Git pour votre code natif ? C’est probablement là que tout le code ouvert est stocké et vous avez probablement des gens qui connaissent assez bien Git.
Voici le problème. La plupart des développeurs IBM i n’ont jamais utilisé Git. Les branches, les fusions et le flux de travail (workflow) Git leur sont étrangers. Ils ne pensent pas que cela puisse être pour eux. Essayez de dire à un développeur IBM i qu’à partir de maintenant, lorsqu’il effectue une modification, il doit extraire sa source d’une branche Git, et voyez jusqu’où vous pouvez aller.
C’est là que notre solution entre en jeu. Un système moderne de gestion de changements comme ARCAD connaît Git. Il utilise des webhooks lors de la création de branches et crée automatiquement des bibliothèques de développement associées sur l’IBM i. Il place ensuite le code source dans ces bibliothèques de développement lors du checkout, prêt à être modifié et compilé. Il place ensuite la source dans ces bibliothèques de développement pendant le checkout, prête à être éditée et compilée. Ce n’est pas très différent.
Avec ce type d’outils en place, comment un développeur IBM i utilise-t-il Git pour assembler ? Il vérifie simplement la source, c’est tout. L’outil fait le reste. C’est juste une option de menu ou un clic droit. Lorsqu’il a terminé ses modifications, une autre option de menu ou un clic droit le renvoie à la branche. C’est le même flux de travail auquel ils sont habitués (maintenant), ils vérifient, éditent, compilent, testent et livrent le changement. La différence est que Git se trouve en arrière plan.
Avez-vous remarqué que dans le paragraphe ci-dessus, j’ai dit qu’ils peuvent prendre une option de menu ? Il est sous-entendu qu’un développeur IBM i qui utilise 5250 peut également le faire. Cette implication est vraie. Le développement sur écran vert avec Git comme contrôle de la source est entièrement pris en charge par ARCAD. C’est une intégration sérieuse.
3. Rendre Git « intelligent » sur les composants natifs d’IBM
Ok alors… problème suivant. Git n’a aucune idée de ce qu’est un IBM i. Il n’a aucune idée de ce qu’est un PF ou une Table. Il n’a aucune idée des dépendances. Alors, comment un build avec des composants IBM i peut-il fonctionner ? En passant ce qui a été changé à un outil qui connaît l’IBM i, voilà comment.
Chez ARCAD, nous appelons cet outil Builder. C’est un build IBM i intelligent. Si vous modifiez une table en utilisant Git comme référentiel de code source, Git transmettra ce que vous avez modifié à Builder. Builder identifiera alors tous les composants connexes et les recompilera automatiquement, dans le bon ordre, dans les bonnes bibliothèques de développement. Encore une fois, l’automatisation est la clé ici. Vous n’avez pas besoin d’un ‘makefile’ ou de scripter chaque changement. Tout est fait pour vous.
La meilleure partie est que votre source est toujours disponible sur votre IBM i. ARCAD utilise Git pour pousser les sources vers les bonnes bibliothèques selon les besoins. Les développeurs travaillent sur l’IBM i dans des bibliothèques avec des fichiers sources qui sont tous natifs. RDi et 5250 sont tous deux pris en charge.
4. Un seul pipeline CI/CD pour les déclarer tous
Ainsi, avec ce type d’outils, votre code IBM i peut suivre le même pipeline que votre open source. Commencez-vous à y voir plus clair ? Maintenant, nous pouvons utiliser le même type d’automatisation pour le code IBM i qui est utilisé pour le code ouvert. Cela ouvre la porte à un véritable DevOps sur l’IBM i.
Par exemple, vous pouvez utiliser Jira pour créer une tâche. L’interface d’ARCAD avec Jira créera le rapport de maintenance correspondant au moment opportun. Cela peut être le cas lorsqu’un développeur fait glisser la tâche « Backlog » à « In-Development » sur un tableau Kanban, comme illustré ici.
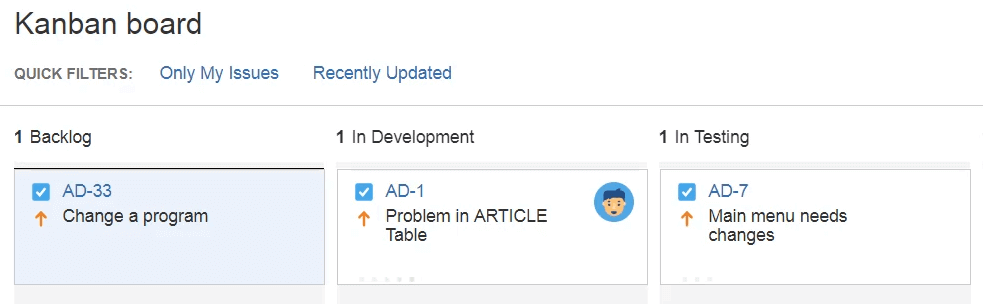
Une branche est créée pour le développeur et, à l’aide d‘ARCAD Skipper, ils développent comme ils le font actuellement, sans grands changements, sans nouveau flux de travail, sans grande courbe d’apprentissage, sans ralentissement de la productivité.
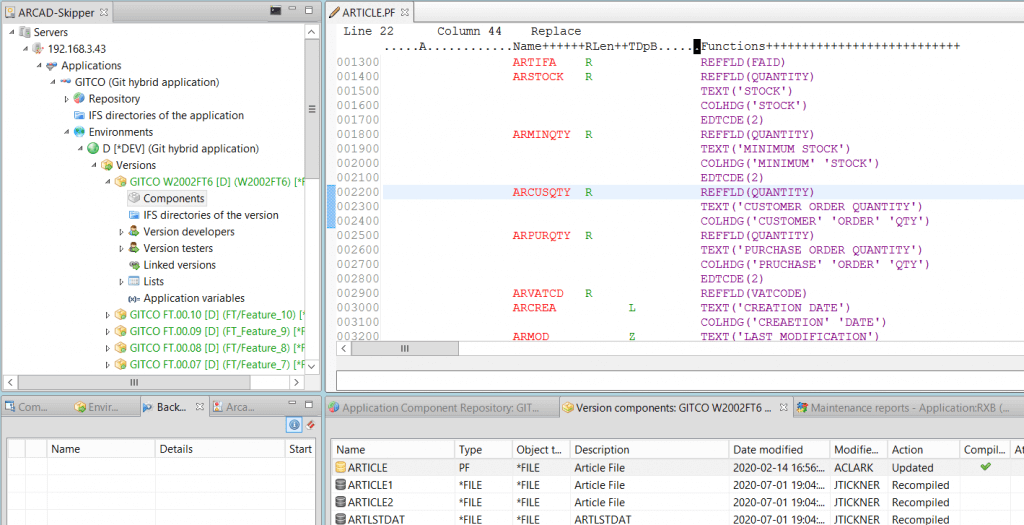
Quand ils sont prêts, ils poussent le changement et l’automatisation prend le relais. La branche est mise à jour dans le dépôt Git. L’événement push déclenche un webhook, quelque chose se produit alors et une action est nécessaire. Quel type d’action ? Examinons quelques possibilités. Regardez l’illustration ci-dessous.
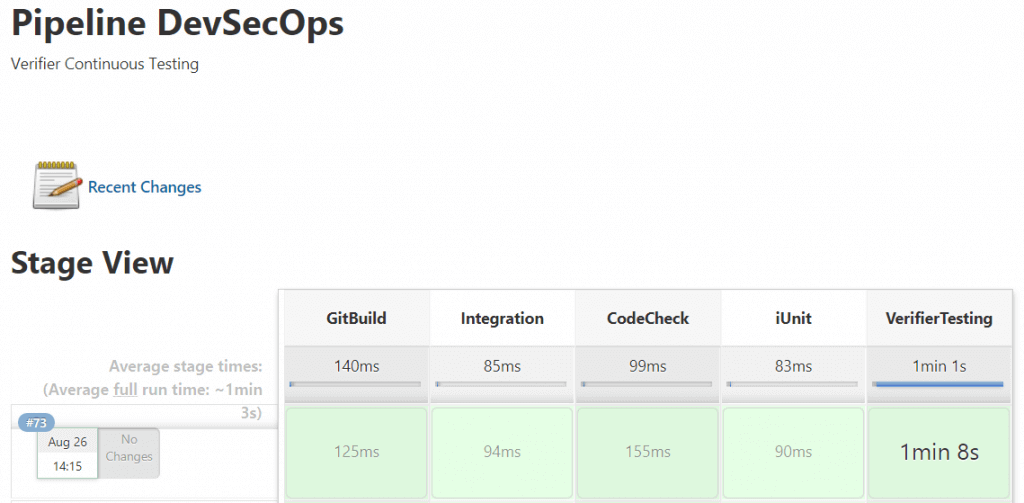
C’est un exemple de pipeline automatisé pour le code IBM i passant dans un environnement de test unitaire. C’est Jenkins qui est présenté dans cet exemple. Lorsque le développeur a appuyé sur push, Git et Builder ont créé ensemble tout ce qui était nécessaire. Pendant l’intégration, le code source a été copié du développement vers un environnement de test sur l’IBM i. Les objets ont été déplacés ou compilés dans la zone de test, c’est un choix que vous faites.
Une fois que la source et les objets sont en place, le pipeline déclenche ARCAD Code Checker. Code Checker examine automatiquement le code source en fonction des normes de qualité et de sécurité que vous pouvez définir. Il s’agit de la première étape de la barrière de qualité pour votre code IBM i.
ARCAD iUnit peut ensuite tester les procédures de vos programmes pour s’assurer qu’elles fonctionnent toujours comme prévu. Ensuite, ARCAD Verifier peut exécuter des tests de régression complets sur l’environnement pour voir si le changement a eu des résultats inattendus que vous n’auriez pas pu prévoir. Tout cela est automatisé.
Vous obtenez des rapports et des résultats tout au long du processus. Vous pouvez les consulter à partir de votre outil d’automatisation, comme Jenkins, de sorte que vous disposez d’un seul endroit pour rechercher les problèmes. Tout cela parce qu’un développeur a choisi une option de menu ou fait un clic droit dans RDi. Vous imaginez le gain de temps ?
Donc, sans trop changer les choses pour vos équipes de développement, ceci pourrait être votre workflow IBM i.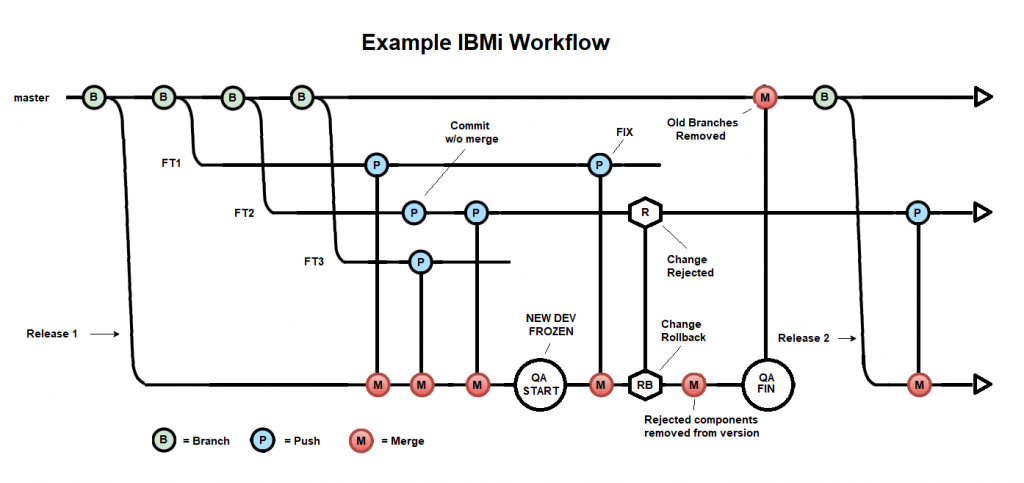
Vous pouvez voir la ligne de code de production sur la branche master en haut. Chacune des branches feature est une modification en cours de développement. Les branches feature sont créées à partir de la branche master. Les développeurs travaillent sur ces branches feature et utilisent l’automatisation dont nous avons déjà parlé. Ils poussent vers les branches feature. Vous pouvez également voir des événements de poussée de chacune des branches feature. Ce n’est pas le développeur qui fait cela, laissez-moi vous expliquer.
Le développeur ne repousse que sur la branche feature. Vous pouvez avoir autant de branches feature que vous le souhaitez. Le développeur peut pousser vers elles aussi souvent qu’il le souhaite. Maintenant, imaginez que vous créez une nouvelle version de votre logiciel, voici une question pour vous. Lorsque vous êtes prêt à mettre à jour la production, préférez-vous le faire changement par changement, fonctionnalité par fonctionnalité, comme vous le faisiez en test ? Ou préférez-vous lancer l’ensemble d’un seul coup comme toute parution ? La dernière solution me semble beaucoup plus facile.
C’est la raison d’être de la branche release en bas du diagramme. Elle est là pour recueillir les modifications apportées par les développeurs sur les branches feature. Les événements push présentés ici peuvent être réalisés par votre service d’assurance qualité lorsque le changement est accepté, par exemple.
Maintenant, rappelez-vous, une branche a une bibliothèque IBM i associée. Donc oui, vous auriez raison de supposer que la même chose s’est produite lors de la création de la branche release. Une bibliothèque a été créée pour stocker la version dans son ensemble. L’illustration ci-dessous est un pipeline CloudBees, Jenkins n’est pas nécessaire, l’automatisation est requise et il y a beaucoup d’outils pour vous aider comme CloudBees, Azure DevOps et Jenkins.
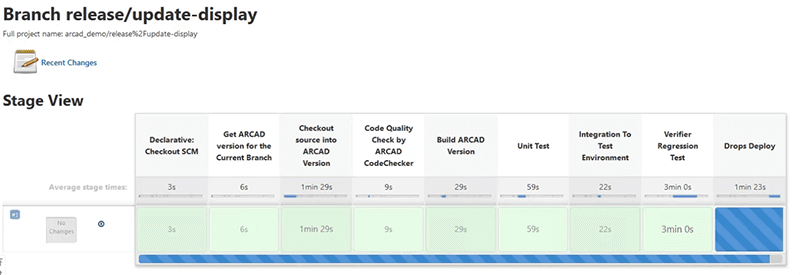
Une fois que les changements sont acceptés pour la version, les événements push indiqués sur le diagramme déclenchent tout ce qui précède. Le processus utilise d’abord les informations de branchement pour déterminer la version correcte de la bibliothèque sur l’IBM i. Avant que le code ne soit placé dans la bibliothèque publiée, il est examiné par Code Checker pour vérifier la qualité et la sécurité. S’il passe ce test, la source est placée dans la bibliothèque et compilée pendant le build. Une fois les objets créés, ARCAD iUnit teste à nouveau les procédures. Si tout se passe bien, les modifications sont automatiquement transférées de l’environnement de test unitaire à l’environnement d’assurance qualité lors de l’étape d’intégration. Ensuite, un test de régression complet est effectué et, si tout se passe bien, les modifications sont déployées sur une LPAR de test.
Tout cela s’est produit parce qu’une branche feature a été intégrée dans la branche release. C’est une automatisation sérieuse et c’est le véritable DevOps sur l’IBM i.
5. Le vrai DevOps avec Git sur IBM i
Je travaille avec les outils dont j’ai parlé ici, et bien d’autres, depuis longtemps maintenant. Je parle de DevOps pour l’IBM i depuis, au moins, les 6 dernières années environ. Ces outils vous permettent de “shift left”. Les problèmes sont détectés au début du cycle de développement quand ils sont beaucoup moins coûteux de les résoudre. Ils sont répétitifs ; ils vérifient automatiquement les choses plusieurs fois au cours du cycle de vie d’un changement. Ils automatisent les étapes que vous effectuez actuellement manuellement. Il s’agit d’un ensemble d’outils modernes qui vous permet de traiter votre code IBM i de la même manière que votre code ouvert. Avec agilité.
La seule chose qui me perturbe, c’est la vitesse à laquelle les entreprises IBM i se sont adaptées aux nouveaux écosystèmes que nous voyons. Ce n’est pas la plate-forme, elle peut gérer tout ce que vous lui proposez. Ce n’est pas le manque d’outils. Comme vous l’avez vu ici, les outils sont disponibles et matures.
Cette solution permet aux développeurs Open et IBM i de travailler ensemble, elle inclut des capacités de référence croisée entre plates-formes et ils peuvent se « voir » mutuellement. Elle permet à un développeur 5250 expérimenté qui travaille dans l’entreprise depuis des années de travailler comme il l’a toujours fait. Elle vous permet d’attirer de nouveaux talents car les (jeunes) développeurs qui sortent aujourd’hui de l’université connaissent déjà Git, Jira et des outils comme Jenkins et ils se sentiront chez eux avec tout cela. C’est une solution qui fonctionne. Elle est disponible aujourd’hui. Alors, qu’en est-il ? Qu’attendons-nous ? Une invitation ?
Eh bien, je vous invite officiellement à examiner le reste du site d’ARCAD et à voir ce que nous pouvons faire pour vous et votre entreprise. Maintenant que tout cela est réglé, Git Going !!!!

Ray Bernardi
Consultant sénior, ARCAD Software
Ray a 30 ans d’expérience dans l’IT et est actuellement spécialiste du support technique avant/après vente pour ARCAD Software, éditeur international de logiciels et partenaire commercial d’IBM. Il a été impliqué dans le développement et la vente de nombreux logiciels de pointe tout au long de sa carrière, avec des connaissances spécialisées dans les produits ALM (Application Lifecycle Management) d’ARCAD Software couvrant un large éventail de domaines fonctionnels, y compris la modernisation d’IBM i et DevOps. En outre, Ray est un intervenant fréquent à COMMON et à de nombreuses autres conférences techniques dans le monde entier. Il est également l’auteur d’articles et de plusieurs publications sur l’analyse et la modernisation des applications, sur SQL et sur la veille économique.

